Wednesday, 22nd April 2026
Is Claude Code going to cost $100/month? Probably not—it’s all very confusing
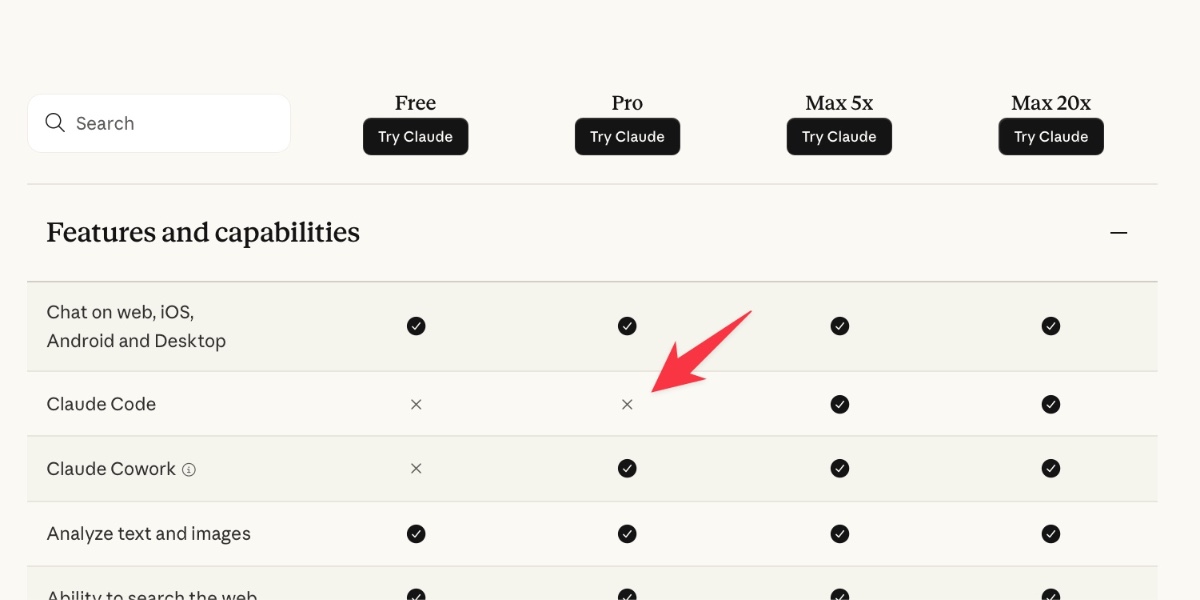
Anthropic today quietly (as in silently, no announcement anywhere at all) updated their claude.com/pricing page (but not their Choosing a Claude plan page, which shows up first for me on Google) to add this tiny but significant detail (arrow is mine, and it’s already reverted):
[... 1,202 words]Changes to GitHub Copilot Individual plans (via) On the same day as Claude Code's temporary will-they-won't-they $100/month kerfuffle (for the moment, they won't), here's the latest on GitHub Copilot pricing.
Unlike Anthropic, GitHub put up an official announcement about their changes, which include tightening usage limits, pausing signups for individual plans (!), restricting Claude Opus 4.7 to the more expensive $39/month "Pro+" plan, and dropping the previous Opus models entirely.
The key paragraph:
Agentic workflows have fundamentally changed Copilot’s compute demands. Long-running, parallelized sessions now regularly consume far more resources than the original plan structure was built to support. As Copilot’s agentic capabilities have expanded rapidly, agents are doing more work, and more customers are hitting usage limits designed to maintain service reliability.
It's easy to forget that just six months ago heavy LLM users were burning an order of magnitude less tokens. Coding agents consume a lot of compute.
Copilot was also unique (I believe) among agents in charging per-request, not per-token. (Correction: Windsurf also operated a credit system like this which they abandoned last month.) This means that single agentic requests which burn more tokens cut directly into their margins. The most recent pricing scheme addresses that with token-based usage limits on a per-session and weekly basis.
My one problem with this announcement is that it doesn't clearly clarify which product called "GitHub Copilot" is affected by these changes. Last month in How many products does Microsoft have named 'Copilot'? I mapped every one Tey Bannerman identified 75 products that share the Copilot brand, 15 of which have "GitHub Copilot" in the title.
Judging by the linked GitHub Copilot plans page this covers Copilot CLI, Copilot cloud agent and code review (features on GitHub.com itself), and the Copilot IDE features available in VS Code, Zed, JetBrains and more.
As part of our continued collaboration with Anthropic, we had the opportunity to apply an early version of Claude Mythos Preview to Firefox. This week’s release of Firefox 150 includes fixes for 271 vulnerabilities identified during this initial evaluation. [...]
Our experience is a hopeful one for teams who shake off the vertigo and get to work. You may need to reprioritize everything else to bring relentless and single-minded focus to the task, but there is light at the end of the tunnel. We are extremely proud of how our team rose to meet this challenge, and others will too. Our work isn’t finished, but we’ve turned the corner and can glimpse a future much better than just keeping up. Defenders finally have a chance to win, decisively.
— Bobby Holley, CTO, Firefox
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.